지난 포스트를 통해 자바로 파일을 복사하는 몇가지 방법을 알아보았다.
이번시간에는 각 코드의 성능을 간단히 확인해 보고자 한다.
[code]
/*
* author 신윤섭
*/
package filecopy;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* Stream을 이용한 파일복사 코드 스니핏
* @author 신윤섭
*/
public class StreamCopy {
/**
* source에서 target으로의 파일 복사
* @param source
* @param target
*/
public void copy(String source, String target) {
//복사 대상이 되는 파일 생성
File sourceFile = new File( source );
//스트림 선언
FileInputStream inputStream = null;
FileOutputStream outputStream = null;
try {
//스트림 생성
inputStream = new FileInputStream(sourceFile);
outputStream = new FileOutputStream(target);
int bytesRead = 0;
//인풋스트림을 아웃픗스트림에 쓰기
byte[] buffer = new byte[1024];
while ((bytesRead = inputStream.read(buffer, 0, 1024)) != -1) {
outputStream.write(buffer, 0, bytesRead);
}
} catch (Exception e) {
e.printStackTrace();
}finally{
//자원 해제
try{
outputStream.close();
}catch(IOException ioe){}
try{
inputStream.close();
}catch(IOException ioe){}
}
}
}
[/code]
[code]
/*
* author 신윤섭
*/
package filecopy;
import java.io.File;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* Buffer를 이용한 파일복사 코드 스니핏
* @author 신윤섭
*/
public class BufferCopy {
/**
* source에서 target으로의 파일 복사
* @param source
* @param target
*/
public void copy(String source, String target) {
//복사 대상이 되는 파일 생성
File sourceFile = new File( source );
//스트림, 버퍼 선언
FileInputStream inputStream = null;
FileOutputStream outputStream = null;
BufferedInputStream bin = null;
BufferedOutputStream bout = null;
try {
//스트림 생성
inputStream = new FileInputStream(sourceFile);
outputStream = new FileOutputStream(target);
//버퍼 생성
bin = new BufferedInputStream(inputStream);
bout = new BufferedOutputStream(outputStream);
//버퍼를 통한 스트림 쓰기
int bytesRead = 0;
byte[] buffer = new byte[1024];
while ((bytesRead = bin.read(buffer, 0, 1024)) != -1) {
bout.write(buffer, 0, bytesRead);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//자원 해제
try{
outputStream.close();
}catch(IOException ioe){}
try{
inputStream.close();
}catch(IOException ioe){}
try{
bin.close();
}catch(IOException ioe){}
try{
bout.close();
}catch(IOException ioe){}
}
}
}
[/code]
[code]
/*
* author 신윤섭
*/
package filecopy;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.nio.channels.FileChannel;
import java.io.IOException;
/**
* NIO Channel을 이용한 파일복사 코드 스니핏
* @author 신윤섭
*/
public class ChannelCopy {
/**
* source에서 target으로의 파일 복사
* @param source 복사할 파일명을 포함한 절대 경로
* @param target 복사될 파일명을 포함한 절대경로
*/
public void copy(String source, String target) {
//복사 대상이 되는 파일 생성
File sourceFile = new File( source );
//스트림, 채널 선언
FileInputStream inputStream = null;
FileOutputStream outputStream = null;
FileChannel fcin = null;
FileChannel fcout = null;
try {
//스트림 생성
inputStream = new FileInputStream(sourceFile);
outputStream = new FileOutputStream(target);
//채널 생성
fcin = inputStream.getChannel();
fcout = outputStream.getChannel();
//채널을 통한 스트림 전송
long size = fcin.size();
fcin.transferTo(0, size, fcout);
} catch (Exception e) {
e.printStackTrace();
} finally {
//자원 해제
try{
fcout.close();
}catch(IOException ioe){}
try{
fcin.close();
}catch(IOException ioe){}
try{
outputStream.close();
}catch(IOException ioe){}
try{
inputStream.close();
}catch(IOException ioe){}
}
}
}
[/code]
이상의 샘플코드를 이용하여 700Mbytes 짜리 파일을 5번 복사하여 그 시간을 측정해 본 결과는 아래와 같다.
테스트는 Win XP Pro sp3, Intel Core2 Duo 2GHz, 2Gbytes, 5400rpm의 노트북용 HDD 에서 JDK 1.6.0_06
을 이용하여 이루어졌다.
결과는 아래와 같다.

Stream을 이용한 파일 복사
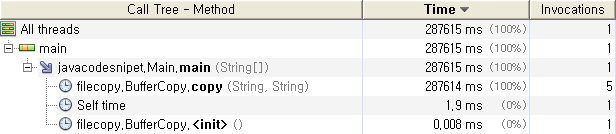
Buffer를 이용한 파일 복사
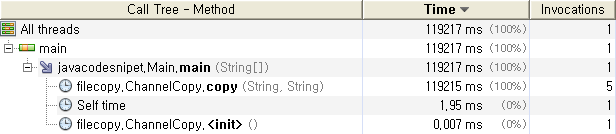
Channel을 이용한 파일 복사
프로파일러를 이용하여 측정한 값이기 때문에 프로파일러의 처리량 만큼의 차이는 있겠지만 상대적 성능 비교
에는 문제가 없으리라 생각 된다.
실측에서도 예상대로 Stream , Buffer, Channel 순으로 파일 복사 시간이 줄어들고 있음을 볼 수있다.
이번에는 조금 더 들여다 보기로 하자. 700m짜리 파일을 한번 복사하는데 어떤 클래스와 메소들이 참여하고
있는지, 그리고 메소드가 몇번이나 호출되고 있는지 확인 해 보는것도 재미있을 것이다.
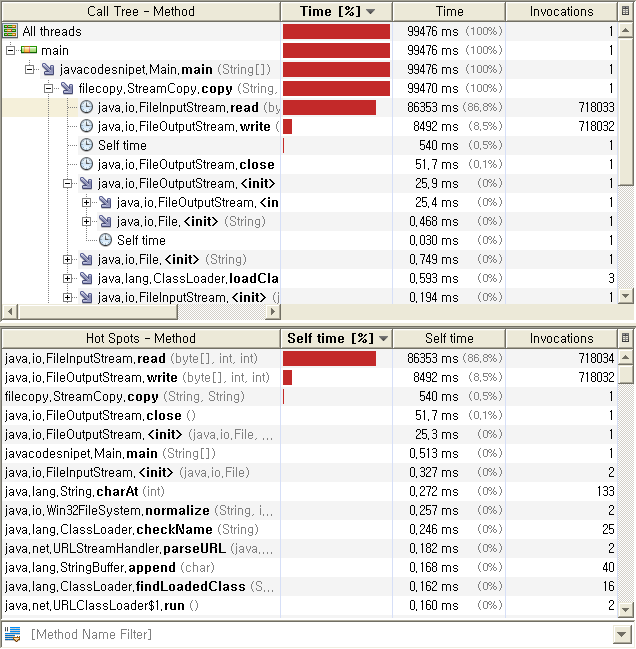
FileInputStream.read()실행에 대부분의 시간을 소비하고 있다.
스트림을 이용한 파일복사이다. FileInputStream.read()메소드가 71만여번 호출되고있으며 실행시간의 대부분을
이 메소드를 실행 하는데 소비하고 있음을 알 수 있다.
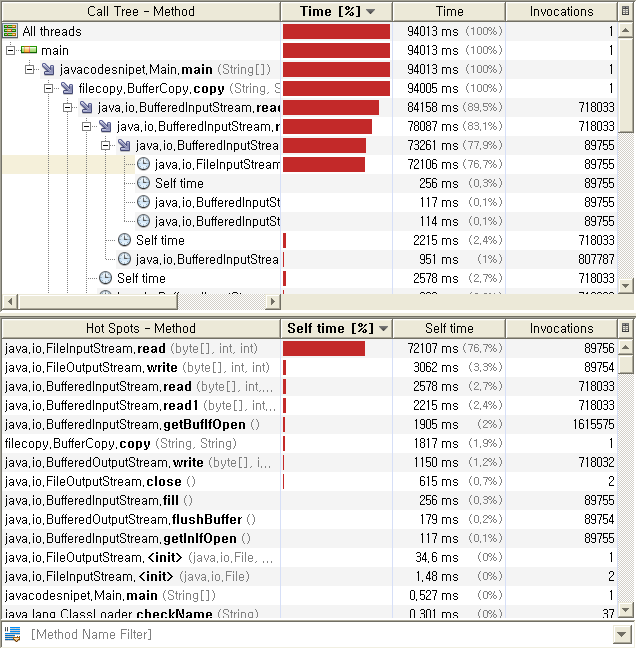
Stream보다는 나아졌다고는 하나 역시 read()메소드가 대부분의 실행시간을 소비하고 있다.
Buffer를 이용한 방법. 위의 Stream을 이용한 방법에 비해 수행시간이 약간은 줄어들었지만 이는 Buffer를 활용
함으로써 FileOutputStream.write() 수행시간을 줄인데 따른 성능 향상이며, FileInputStream.read()메소드는
약 9만번 호출되고 있다.
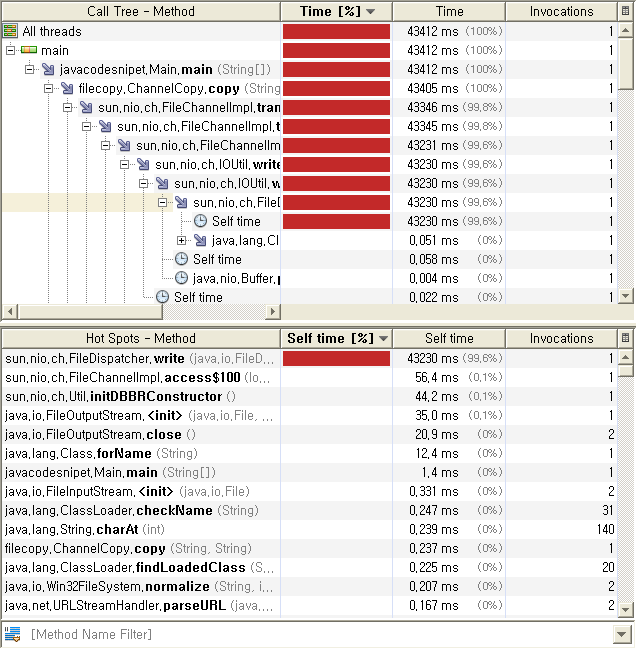
위 두 방식과는 확연히 다른 동작 성향을 보여주고 있다.
마지막으로 채널을 이용한 파일복사의 경우 위 두 경우와 비교하여 호출되는 메소드나 호출횟수등 전혀 다른
동작 성향을 보이고 있다. read 도 하지 않은채 FileDispatcher.write() 메소드를 단 한번 호출 하는것으로 파일
복사를 끝내고 있다. 이 FileDispatcher.write() 하부구조에서는 OS의 네이티브IO를 호출하고 있으리라 미루어
짐작할 수 있다.
이상으로 파일복사(스트림전송)의 세가지 방식과 그 성능에 대해 간략하게 알아보았다.
위 실험 결과는 크기가 비교적 큰 파일의 복사에서 나타나는 성향며, 다수의 작은 크기의 파일을 복사한다면
그 결과가 달라질 수도 있음을 밝혀둔다.
io작업이 필요한데 JDK 1.4 이상의 버전을 이용할 수 있다면 나은 성능을 보장하는 nio를 사용하지
않을 이유가 없어보인다.
 sample.zip
sample.zip